Способов обойти проверку на уникальность текста, «обойти антиплагиат» — достаточно много. В сети хватает как описаний методологии, так и сайтов, которые предлагают такую обработку текста как услугу.
В этой области постоянно появляется что-то новое, так как системы проверки со временем худо-бедно учатся распознавать тот или иной способ. По моим ощущениям те, кто придумывает новые ухищрения — идут на пару шагов впереди, поэтому ситуация всегда немного не в пользу тех, кто проверят…
Однажды, размышляя об этом, я уподобился Архимеду, запрыгав вокруг компьютера восклицая «Эврика!». Я не знаю, первый я догадался до этого или нет, но способ очистить текст от приемов обхода, причем от любых, даже тех, которые еще не придуманы — оказался, как и все идеальное, простым до предела.
Изложу ход своих мыслей.
Все существующие на сегодняшний день способы обойти антиплагиат сводятся к трем направлениям
- «невидимый символ» — внутрь слов или вместо пробелов в текст вставляются специальные символы, которые Word отобразить не может, благодаря чему текст остается понятным для читателя-человека. Системы проверки символ «видят», поэтому не находят в тексте заимствований, ведь с их «точки зрения» — присыпанный такими символами текст совершенно не похож на тот же самый текст, который таких символов не содержит… Подобное описано у меня в статьях про невидимый символ и обход с пробелами.
- «спрятанный текст» — внутрь текстового файла внедряется подчас бессмысленный, но уникальный текст. При этом для читателя-человека он невидим, но при проверке учитывается. Так как объемы внедряемого текста могут быть большими, мы в итоге получаем приемлемую уникальность. Например, если взять 10 000 символов плагиата и запрятать в текстовый файл 40 000 символов уникального текста, получим общую уникальность текста 80%. Подробнее я про это писал в статьях про спрятанный текст и много позже в статье о том, как спрятанный текст найти.
- третье направление самое творческое, текст при этом, как правило, обрабатывается вручную. Это направление подразумевает припрятывание кусков уникального текста в самые различные места в файле, например за рисунки, в автофигуры, которые затем задвигаются за край страницы, или же изменение слов способом, описанным в статье про обход со спрятанными буквами и т. п.
Что общего между всеми тремя направлениями?
А общее — то, что для читателя-человека текст должен остаться неизменным. Однако для машины это должен быть другой текст, за счет тех или иных ухищрений, так или иначе упрятанных от взора читателя-человека.
И что это нам дает?
Все просто, правда? Если мы возьмем обработанный текст, кто-то один его будет диктовать, а другой вновь наберет, мы получим чистый текст не так ли? Именно так, только это слишком сложно.
А что будет, если взять и распечатать текст из файла, в котором использован тот или иной способ обхода? Я много экспериментировал, и пришел к выводу к такому выводу: ничего. То есть, при печати на бумагу выводится только интересующий нас текст, без всяких там «невидимых символов» и «спрятанного текста». Если распечатать текст, а потом распознать его, мы получим чистый текст! Да, это так, но это по-прежнему слишком сложно.
А что будет если текст не печатать, а экспортировать в PDF прямо из Word, или использовать для этого стороннее ПО (PDF Creator или The Bullzip PDF Printer). По идее второе — надежнее, но мои эксперименты показали, что, по крайней мере пока — совершенно все равно как превращать текст в PDF, тенденция сохраняется — то, что было видимым — остается видимым, а то, что было спрятанным — остается спрятанным (за редкими исключениями, об этом в конце). Если взять такой PDF-файл и распознать его какой-либо программой, например ABBY FineReader, то мы получим чистый текст! И да, это уже совсем не сложно.
Почему это работает?
Все способы обхода основаны на том, что видим мы одно, на самом деле в текстовом файле так или иначе спрятано другое. Экспорт в PDF и последующее распознавание позволяет нам, фактически, отделить то, что мы видим от всей остальной «подноготной». Ну а проверив такой текст в той или иной системе проверки мы увидим его истинный результат.
Немного тонкостей
Надо заметить, что описанный способ не дает напрямую ответа на вопрос, который многих интересует — есть ли в проверяемом тексте приемы обхода? Косвенно (но иногда — очень красноречиво) о том, что они были, может свидетельствовать различный показатель уникальности у одного и того же текста до распознавания и после. Однако, если вы видите, что до распознавания и после него процент уникальности остался прежним, это не дает гарантии того, что приемов обхода не было. Возможно, система проверки просто не нашла заимствований, которые на самом деле есть. Это может происходить по разным причинам, начиная с очевидного: текста, откуда было что-то заимствовано попросту нет в открытом доступе и базах систем проверки… И заканчивая такими экзотическими случаями, когда текст — вот он, лежит в сети, находится поисковиками, но почему-то напрочь игнорируется той или иной системой проверки. Такое тоже случается, но это уже тема для отдельной статьи.
Тесты, методика
Проверим, как это работает. Учинить проверку я предлагаю при помощи «Антиплагиата», все-таки его используют чаще всего. На всякий случай уточню — набор действий, которые будут произведены над «подопытными» файлами, не зависит от того, где и как вы их потом собираетесь проверять.
Для опытов я взял три файла с научными статьями, про которые мне точно известно, что в них используются те или иные приемы, повышающие уникальность. Все три файла выбраны из таких, которые «Антиплагиат» не помечает подозрительными.
Дальше все достаточно просто:
- я удаляю из файлов все метаданные — сведения об авторах, аннотацию, ключевые слова, список источников;
- сохраняю файлы в таком виде с названием «Исходный образец — #» используя исходный формат файла (если был DOC — сохраняю как DOC, если был DOCX — сохраняю как DOCX и т. п.);
- сохраняю (экспортирую) все три файла в PDF, используя для этого стандартные возможности MS Word;
- используя ABBY FineReader 12 я распознаю все файлы;
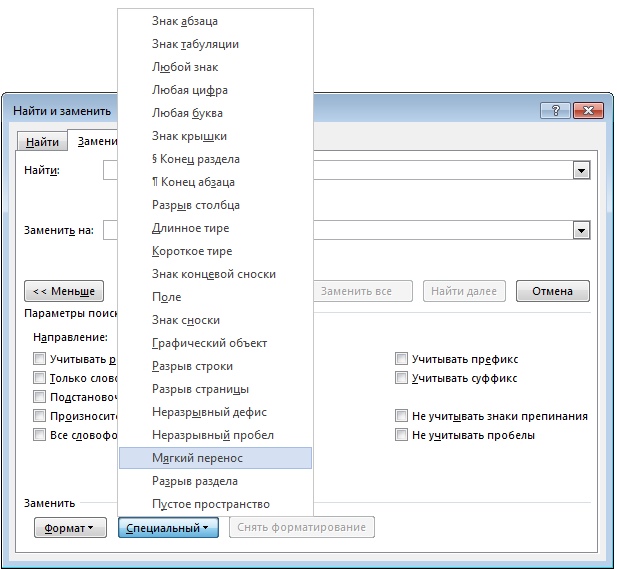
- в полученном после распознавания тексте надо удалить «мягкие переносы», которые очень любит расставлять FineReader — они могут влиять на точность проверки в некоторых программах. Для этого открываем инструмент поиска и замены в Word, устанавливаем курсор в верхнюю строчку, нажимаем в левом нижнем углу окна кнопку «Больше», в открывшейся части, внизу, кнопку «Специальный», выбираем из списка «Мягкий перенос», нижнюю строчку оставляем пустой и нажимаем кнопку «Заменить все» (как показано на рисунке);
- получившиеся файлы я сохраняю в формате DOCX с названием «Очищенный образец — #».
Ну а теперь настало время загрузить получившееся в «Антиплагиат»:
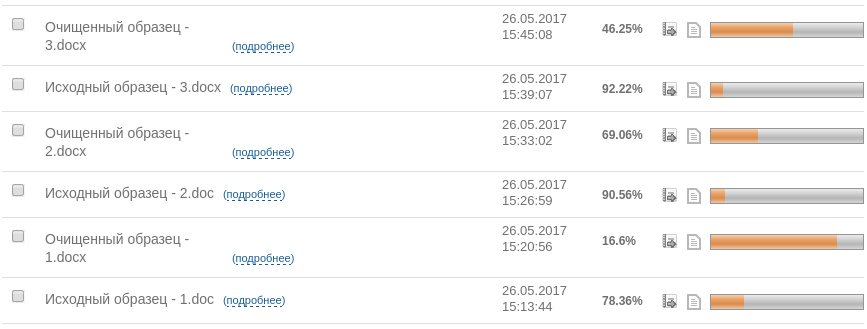
Результат проверки тестовых образцов в системе «Антиплагиат»
Результат, думается, не требует большого количества комментариев. Как видите, после распознавания текст «внезапно» получил совершенно другую оценку.
В завершении хочу добавить, что достаточно давно — около года — экспериментирую с распознаванием и последующей проверкой текстов. Совершенно определенно можно сказать, что «честным» текстам эта процедура никак не вредит, вызывая отклонение от результат исходного образца в 1 — 3%. Так же повторюсь, что совершенно все равно какой способ обхода был использован — распознавание показывает нам истинную оценку текста.
Еще немного тонкостей, или что делать, если текст плохо распознается
Да, контролировать качество распознавания текстов все-таки нужно. Всего два раза, но я сталкивался с тем, что PDF-файлы распознавались с кучей ошибок и как-то странно. Почти уверен, что это связано с приемами, влияющими на уникальность. Посудите сами — если вы делаете приличный размер шрифта, интервал между буквами, и распознаете текст из PDF, даже не выводя его на печать (то есть с точки зрения FineReader — это практически «идеальный текст»), а он распознается с ошибками… Что еще могло повлиять, особенно учитывая тот факт, что другие тексты распознаются нормально?
Столкнувшись с проблемой впервые я достаточно долго с ней провозился, пока не пришла идея конвертировать текст еще раз — из PDF в многостраничный TIFF, то есть, фактически, в изображение — связи с исходным текстом и таящихся в нем уловках не останется никакой.
Я использовал Ghostscript:
ghostscript -o file.tiff -sDEVICE=tiffgray -r720x720 -g6120x7920 -sCompression=lzw file.pdf
Можно использовать какой-либо еще конвертер, главное, чтобы он позволял вставить значение DPI. С ним можно экспериментировать, оно должно быть достаточно большим — по моим ощущениям 500 — 700. Вариант, который показался мне оптимальным для Ghostscript уже заложен в строке выше.
После этих манипуляций все распознавалось «на ура». Многостраничный TIFF можно сразу «скармливать» FineReader’у, он с ними отлично умеет работать.
Вместо заключения
Фокус с распознаванием текста добавляет уверенности в результате проверки, если есть сомнения в том, что автор «не чист на руку». За этот и прошлый год мне пришло достаточно большое количество писем с просьбой оценить тот или иной текст и попытаться найти в нем «что-нибудь этакое». Как я уже писал выше — распознавание позволяет получить «чистую» оценку на текущий момент, но не дает однозначного ответа на вопрос — были ли в тексте какие-либо приемы, повышающие уникальность?
С одной стороны это кажется достаточным — мы знаем истинную оценку текста, не все ли равно, было там что-то или нет? С другой — не так уж и редко встречаются тексты, в которых с одной стороны есть приемы, а с другой стороны — даже после чистки они выдают приличный результат.
Зачем авторы их «обрабатывали»? Ну будущее? На всякий случай? Или, может быть, когда они проверяли — что-то находилось? Варианты есть разные. Чем больше я занимаюсь проверкой текстов, тем больше убеждаюсь, что результат проверки текста на уникальность в «Антиплагиате» или любой другой системе — понятие достаточно эфемерное и не гарантирующее ровным счетом ничего, однако об этом я порассуждаю в следующий раз.



{kind=link}
Нашел очень простой способ — сохраняем документ в Word в PDF.
Открываем полученный файл в нем же!!! Да-да, Word открывает PDF. Все должно стать явным.
Иван, Вы торопитесь 😉 Что можно получить от преобразования текста в PDF а потом обратно? Word не распознает файлы, а, как Вы сами и написали, _открывает_ их.
Для примера — способ обхода, описанный вот тут — https://apavlov.ru/obhod-antiplagiat-3/ — благополучно переносит процедуру «сохранить текст из Word в PDF и открыть его в Word» и продолжает действовать. То есть способ — не панацея. Можно, конечно, продолжать тесты, но зачем?
Текст нужно именно распознавать, только это дает гарантию того, что на уникальность проверяется именно (и исключительно) то, что было видно при просмотре файла. Суть всей статьи выше — в этом.
PDF у меня фигурирует только как формат — посредник между Word и FineReader, само по себе преобразование текста в PDF ни от чего его не очищает и ничего не дает. Если торопитесь и не хотите распознавать — сохраняйте текст в формат RTF, он гораздо проще, чем современный DOCX и многие «ухищрения» сохранение текста в этот формат не переживают. Но тоже не все. Так что самое надежное — распознавать.
Ошибаетесь, Александр. Word очень даже распознаёт текст, даже если открывать PDF со сканированным документом, то есть, фактически изображение. Правда, всё это при условии, что при установке офиса был установлен компонент «Средства Office» —> «Распознавание символов (OCR)».
Я почему-то думал, что Microsoft забросил идею со своей OCR, хотя раньше пользовался… Завтра непременно посмотрю, что там есть в компонентах Office. Спасибо за интересную наводку! Я сейчас использую Tesseract, не без нареканий.
Раньше за распознавание текстов отвечал отдельный инструмент — Microsoft Office Document Imaging, который «выпилили» с версии 2010. Я думал, что OCR в офисе совсем нет, оказывается он просто перестал быть отдельным компонентом. Подтверждаю — Word распознает текст, если открывать PDF. Но есть одно важное НО — если в PDFе содержится текст (т.е. он находится в таком виде, когда его можно выделять и копировать), то Word берет его, и этот процесс некоторые модификации могут пережить (проверял). То есть, для того, чтобы был верный эффект, недостаточно из Word текст сохранить в PDF и тут же снова открыть в Word — надо текст сохранить в PDF, PDF постранично «расчекрыжить» на изображения, из получившихся изображений назад собрать PDF и уже это засовывать в Word. Вот тогда он распознает, причем неплохо. Даже таблицы более-менее распознает. В любом случае, спасибо за интересную наводку — не знал про эту возможность!
Cистема Антиплагиат прекрасно проверяет и pdf файлы.
Антиплагиат, да, PDF проверяет. По Вашему мнению этот как-то связано с тем, что написано в статье?
Просто «Антиплагиат» и так найдет заимствования, без дополнительной обработки файлов. Проверено на себе. А так Вы молодец, провели большую работу, возможно кому-то пригодиться Ваш опыт, но сотрудники системы «Антиплагиат» (я не отношусь к их числу) тоже не сидят на месте, и тем самым развивают свою систему, в работе которой порой встречаются ошибки.
Спасибо на добром слове. Соглашусь, что «Антиплагиат», безусловно не стоит на месте, и уже умеет обнаруживать достаточно большое количество всяких «хитростей», но я на него не надеюсь. Просто потому, что искусственное повышение уникальности текста — большой бизнес (не верите — вбейте в поисковик «повышение уникальности текста»). Люди так зарабатывают деньги, а, как известно хочешь жить — умей вертеться.
Вот буквально сегодня мне попался очередной «обработанный» текст, который Антиплагиат глотает за милую душу и даже не пишет, что он «подозрительный». Весной попалась «обработанная» статья от доктора наук, так что не только студенты пользуются услугами по повышению уникальности текста 🙂
Сейчас все проверяемые тексты в обязательном порядке перегоняю в PDF и потом распознаю. Почему именно в PDF? Потому, что этот формат отвечает двум требованиям. 1 — в него можно сохранить текст сразу из Word, и 2 — его сразу можно «скормить» FineReader’у. Само сохранение текста в PDF, как таковое, ничего в нем не меняет. Важно текст именно распознать — это отсекает видимое от «поднаготной», то есть после этого можно быть уверенным, что проверяешь именно то, что видел на экране.
К тому же, текст прогоняется через несколько систем, как минимум это «Антиплагиат» и «ETXT Антиплагиат», бывает что-то еще. Кстати, две эти системы редко дают одинаковый результат, интересно, правда? А бывает что дают противоположный. Есть в сети тексты, которые «Антиплагиат» не видит просто в упор. Хотел написать даже статью про это, но она вышла какая-то уж очень злая, так что я ее не выложил.
С одной стороны — да, перестраховка. Да, пардон, геморрой. Но всяко проще, чем потом статьи ретрагировать 🙂
Да просто этот ваш антиплагиат — говно. И я не удивлюсь, что этим ребятам доплачивают, чтоб он оставался им. Все эти «левые» символы — видимые (a и а), невидимые ( ) — в легкую могут быть отфильтрованы и заменены с учетом контекста. Спрятанный в разных местах текст — легко выявляется: если это за картинкой — ctrl+a ctrl+c ctrl+v в текстовик и meld в помощь, если это код документа — берем коэффициент погрешности и смотрим, если разница общего кол-ва символов кода и выведенных человеку на монитор символов больше коэффициента, то кое-кто, по-русски выражаясь, пи**ит. И это вообще — что первое пришло мне на ум, все это в легкую решается.
Василий, здравствуйте! Во-первых, давайте общаться без лишних эмоций, ок?
Мне интересно, а как Вы предлагаете из кода вордовского файла вычленить только те символы, которые выводятся на экран?
А что это даст, если «левые» символы де-юре, с точки зрения этого кода, тоже выводятся?
Я начинал с того, что искал некий подобный способ для выявления каждого конкретного метода обмана системы. В итоге это оказалось не эффективным, а когда нужно проверить много текстов — еще и излишне трудоемким. Плюс ненулевая вероятность что-то не заметить. В этом плане распознать текст — проще, потому что:
1) каким бы методом не нахитрили в тексте, старым, новым, известным, неизвестным, с вероятностью 100% распознается только видимое.
2) в итоге надо сравнить результат проверки двух файлов, и он либо сходится, либо нет. Это видно сразу, без подсчета всяких коэффициентов.
Поэтому мне распознавание кажется более простым и надежным вариантом.
Как убрать техническое поднятие АП??? Помогитееее
Ммм… Вероника, прям вот вся статья об этом. Даже не знаю, что еще сказать…
Очень полезная информация. Наконец то я нашла то что искала. Спасибо.
Как убрать все символы обхода системы антиплагиата? Исходника нет.