Несмотря на то, что все способы обхода антиплагиата в конечном итоге сводятся к трем направлениям, и ничего нового я пока не видел, хочу написать про еще один, уж очень часто он в последнее время встречается.
Начнем с кусочка текста. Не вижу смысла его как-то прятать, скажу лишь, что истинный автор опубликовал статью, содержащую этот текст, в 2015-м году. А в 2018-м к нам в редакцию пришла статья, содержащая этот текст, только уже другой автор пытался выдать его за свой, используя обсуждаемый нами способ обхода.
Вот смотрите:
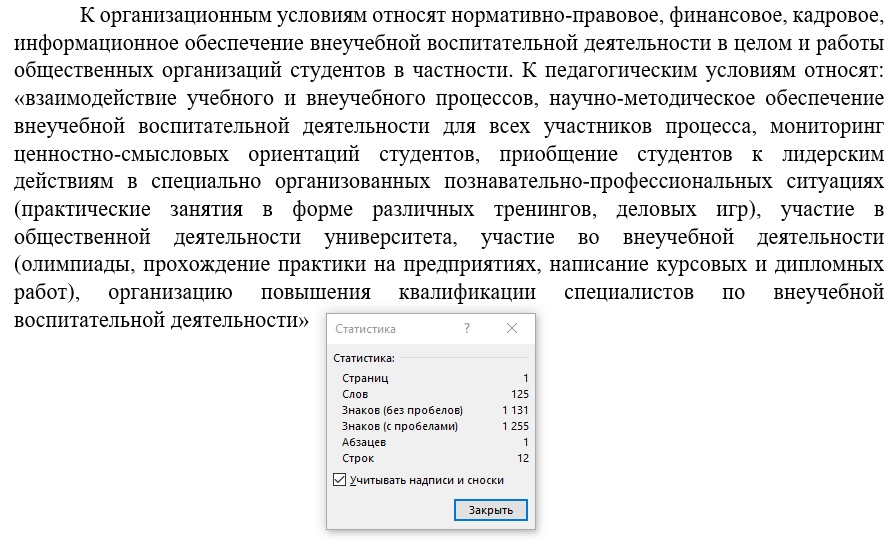
Пытливый читатель, если захочет, может пересчитать слова и увидеть, что на самом деле их не 125, а меньше. Это и не удивительно, потому, что в тексте имеются спрятанные слова, которые сбивают с толку программы при проверке уникальности.
Очистим формат (Ctrl + пробел):
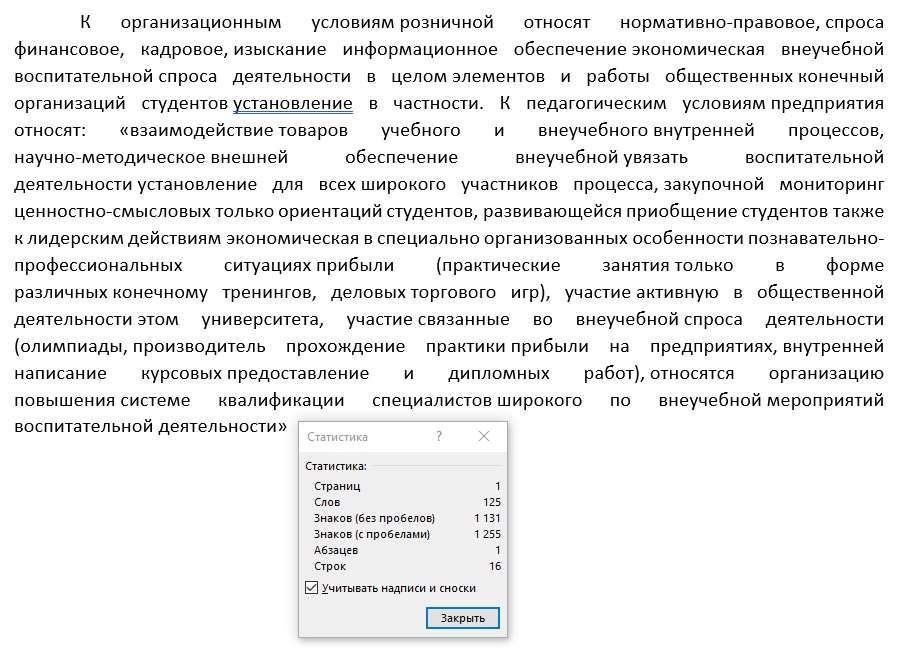
Вот они, всплыли. Сразу видно, что объем текста увеличился. Однако не все так просто! Ведь если текст большой, обнаружить такие слова может быть достаточно сложно. Будем упрощать эту задачу.
Берем исходный текст, выделяем его весь, открываем свойства шрифта, на вкладке «Дополнительно» устанавливаем следующие значения: масштаб — 100%, интервал — обычный, смещение — нет.
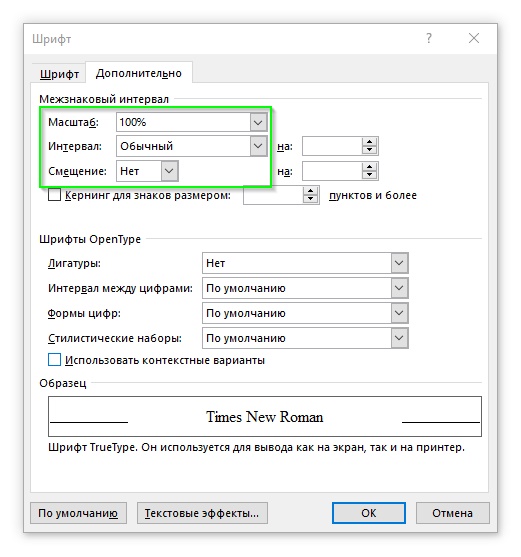
Ситуация начала проясняться. В длинных пустых интервалах, которые легко заметить даже в объемном тексте, припрятанные слова, просто пока их не видно.

Поставим курсор в одно из этих мест, выполним правый клик и в контекстном меню и выберем пункт «Шрифт…». Нас здесь интересует выбранный для этих слов цвет шрифта.
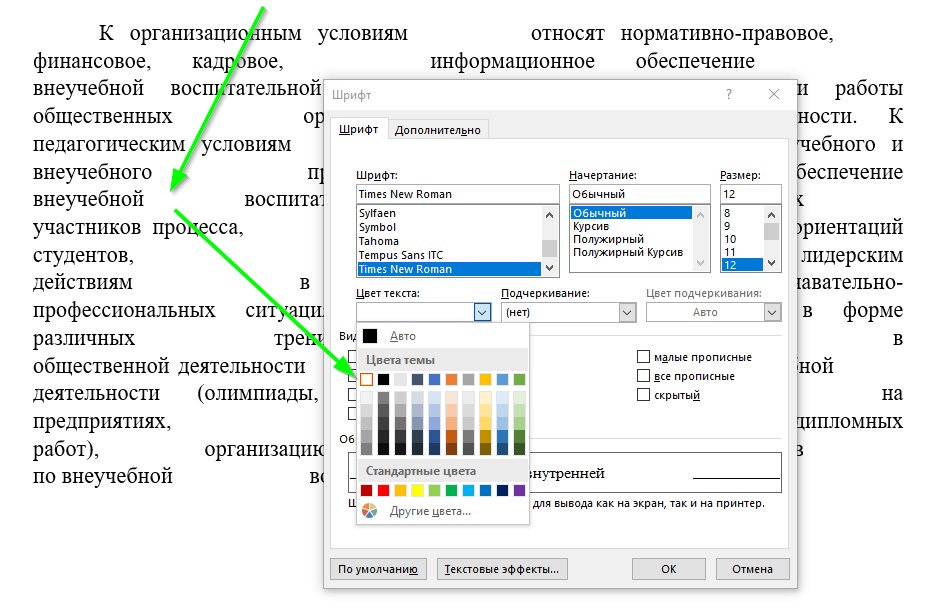
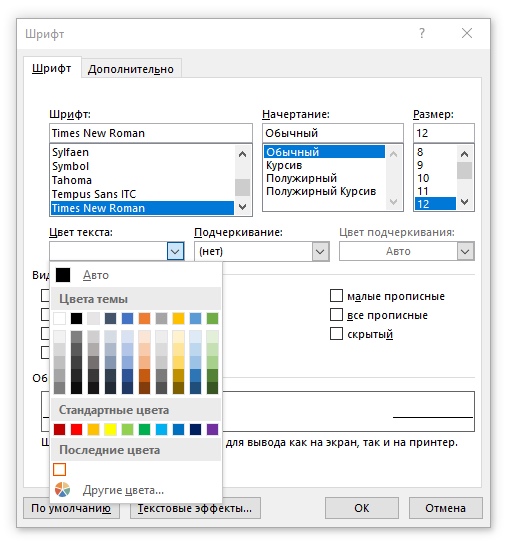
В данном случае цвет белый, но следует учитывать, что он не обязательно будет таким. Для примера, я могу задать вот такой цвет:

Как видите, я изменил одно и значений RGB на одну единицу. Для человеческого глаза это по-прежнему точно такой же белый, но для машины это — другой цвет. Это лирическое отступление о том, что не имеет смысла попросту искать в файле белый шрифт. Его может не быть. Например, если бы в нашем случае обманщики использовали бы эту хитрость, то мы увидели бы цвет не в стандартной палитре, а вот где:
А если бы просто решили проверить, есть ли в файле белый шрифт, то ничего бы не нашли.
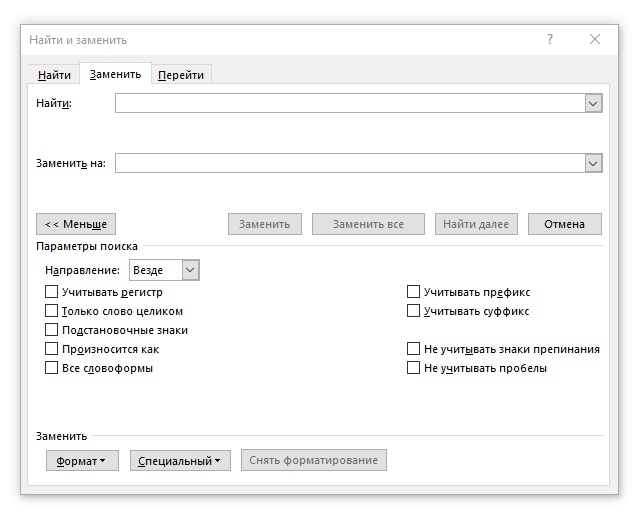
Заканчиваем с лирикой и возвращаемся к нашему файлу. После того, как мы определили, какой же цвет использован, просто заменим этот цвет на какой-нибудь другой. Сделаем это с помощью инструмента поиска и замены. Для начала нажмем кнопку «Больше», чтобы открыть дополнительные параметры. Теперь окно должно выглядеть так:
Устанавливаем курсор в верхнюю строчку, ничего не вводим, нажимаем кнопку «Формат», и открыв пункт «Шрифт» зададим цвет спрятанных слов, в нашем случае обычный белый из стандартной палитры (почему-то в Word он называется «Фон 1»). Затем устанавливаем курсор в нижнюю строчку, и аналогичным образом выбираем красный цвет. Должно получиться вот что:
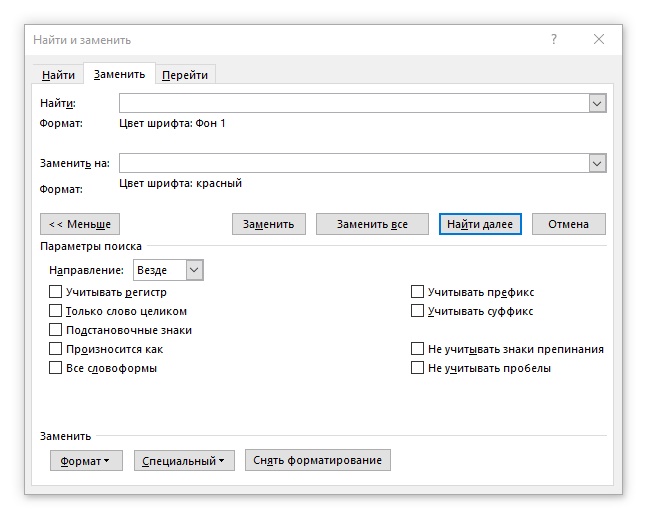
Нажимаем кнопку «Заменить все» и наслаждаемся результатом — слова, которые были спрятаны, не только видны, но и выделены красным цветом:

Вот, собственно, и все. Будьте внимательны, за последние пару месяцев тексты, которые обработаны этим способом, встречались очень часто!
Как застраховаться от подобных трюков? Пытаться их все найти — слишком сложно, к тому же, способов много — никогда нельзя быть уверенным, что в проверяемом тексте ничего такого нет… Чтобы не быть голословным — скажу, что в нашем подопытном файле используется еще один способ обхода, известный давно, но получивший широкое распространение в последнее время. О нем я расскажу в следующей статье. Поэтому, как я уже писал ранее, достаточно проверяемый файл сначала экспортировать в PDF, а затем распознать. Это не дает прямого указания на то, был ли обработан проверяемый текст или нет, зато позволяет получить чистый результат. А для сравнения можно проверить оба варианта текста — до распознавания и после. Посмотрим, что у нас получится, если проделать этот трюк со статьей, на примере которой мы сейчас обсуждаем этот способ обхода.
До распознавания:

Кстати, обратите внимание на текст в окне программы AntiPlagiarism.net (выше) — здесь припрятанные слова тоже видны, из-за этого вместо текста мы видим практически полную бессмыслицу. К сожалению, на практике это не всегда удается заметить, на это и расчет… Так что — страхуемся, распознаем! И получаем:

… И получаем истинный результат для этого текста. Комментарии, я думаю, не требуются.



Я делал дипломку сам, почему-то уникальность меня возмутила 32%. Учитывая 90 страниц текста, переделывать было долго, психанул и залил на https://***********, текст вернули очень быстро, и без изменений. То есть она обработана таким же способом?
Да, обработана. Не обязательно этим способом, но каким-то одним из нескольких.
Вообще, по-моему, это очередная попытка впихнуть сюда рекламу какого-то сервиса.
Здравствуйте Александр!
Я работаю на кафедре, проверяю ВКР на оформление и прогоняю через Антиплагиат.
Сегодня мне пришла интереснейшая работа, в связи с чем я прочитала все ваши статьи данной рубрики, но ответа не нашла.
Первое, что бросилось в глаза — некоторые слова не выделялись по буквам, только все слово целиком. Очищаю формат — появляются два слова.
Это не спрятанный белый текст, а какая-то иная функция. Возможно через XML (плохо в этом разбираюсь)?
Распознать распознала, но не дает покоя — как же это сделано?
Здравствуйте! Извините за долгий ответ!
Делают разными способами, что-то прямо в Word можно сделать, что-то «намутить» в XML, что-то с помощью специальных сервисов или ПО.
Сейчас большинство систем проверки учатся такие вещи распознавать. Антиплагиат.ру находит очень хорошо, ETXT похуже, но тоже находит и т.п.
То, что системы проверок постоянно учатся, привело к тому, что и способы обхода постоянно морфируют. Поэтому понимание того, как это было сделано в данном конкретном случае — хоть и бывает интересным, но практически ничего не приносит. Т.к. вероятность того, что следующий текст будет обработан именно точно так же — очень мала.
Собственно, в этом причина того, что я практически перестал пока писать на эту тему.
Тут нужен, так сказать, системный подход 🙂